McEs, A Hacker Life
101 bugs in your text rendering engine
RESOLVED FIXED ten and otherwise CLOSED a few other bugs yesterday, Pango
bugs are down to 101 now. A few more can be fixed easily, but we are running out of trivial bugs :). Most of the remainings are medium to large feature requests.
Alice and Bob
Dave: You are ignoring the time that takes for light to travel to the camera, which is probably not negligible, given the
time dilation hint in the problem statement. ;-)
Posts highly enjoyed reading today(*) on planet:Nokia 770 - Romance in your pocket by ChipX86
$100 Laptop / OLPC (One Laptop Per Child) by Jim Gettys
Would like to name Rodrigo's
DSL Problems too, but that probably has not been much of a joy for him. I mean, hours without internet.
Time to answer
Questions to answer.
(*) Since last time I woke up.
Pango+Performance progress
Did lots of new work on Pango. Made a parallel patch to
Billy's for
caching glyph extents. And also closed a long-time bug about
supporting OpenType for Latin (and most other) scripts. The
SIL guys helped a lot. Just compare the
gedit rendering with
notepad rendering. No more GPOS problems should be seen on the console too.
As for optimizations, with over 160 members in the
performance list, all discussion has moved there. We probably will post summaries on the
planet from time to time. For now, this is a plot comparing pango-1-10 branch with HEAD that has got all the optimization work:
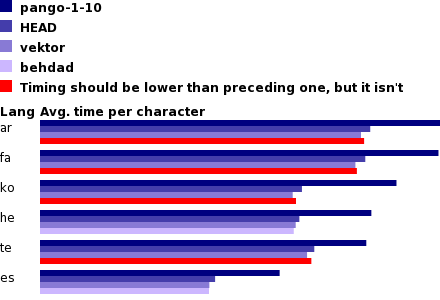
The graph is made with ellipsization turned on, so the speedup is not as much as it should have been compared to previous posts.
Last point on performance, if you've not heard already, the
latest LUGRadio episode talks about our work, making fun of my and Federico's name. Bastards :-).
All in all, I'm loving my new Pango involvement. Just if I could get to some other work too...
Pango 'Extra Lean' 1.11.0 released
That's what
happened. And the
ChangeLog entries for the past two weeks. All
Federico's awesome optimizations are in there, plus a bunch more.
Funny pictures and photos (Thanks
Behnam.)
Red Hat Fedora Poll. Strangely, it's called Fedora Community Poll instead. Ah, by the way, became a
Fedora Ambassador to Canada. Don't wait, become a
Fedora ambassador to your area.
Senko's missing piece of GNOME is funny. It would be cool to have a "Windows migration assistant" that keeps popping up balloons all over the place, shuffling your applets and icons every once in a while ;-).
More on life
Finally posted photos of
jdub's visit to Toronto. Click on the photo and navigate.
RED HERRING
report on Google Summer of Code that quotes me. Typo in my name (again).
Finally
reported to kernel bugzilla the bug with \r at the end of the interpreter line, like shell scripts with \r\n line-termination.
Wanted to make a Pango 1.11.0 release, but noticed that I have to wait until a glib 2.9.0 release is out.
Photos For Imperfect World, an amazing commercial.
GNOME Foundation Board of Directors time again
[Some intro for those not following
Planet GNOME:]
So this is the time of the year that candidacy statements come in for the GNOME foundation board of directors. Having been receiving those for a few years now, mostly from the same set of people every year, it was getting less and less important to read them carefully and choose accordingly, but this year it was different.
Thanks to
Dave Neary who brought up the issue of
reducing the board size, the
foundation-list enjoyed an unusual, yet healthy, traffic
last month. As a result, the board size was reduced (after a referendum) from 11 to 7. As a positive side effect, the election atmosphere is already different, in a good way.
As greg was saying on IRC, the candidacy turnout is pretty good, specially for seven positions. But more interesting to me are candidates like
Quim Gil and
Anne Østergaard, who are both very strong matches for the kind of people we need in the board IMHO. It may not be obvious, but an ideal board of directors is probably not a board of celebrities, and having non-super-hackers in the board is probably an step in the right direction. Not that I believe super-hackers do not make good board members, not at all. Just that super-hackers are more needed in their hacking, or their jobs. Either they are too busy to spend enough time on the board, or they have enough time to spend on the board, but the project as a whole can benefit more if they spend that time on leading their own projects. It doesn't mean that super-hackers are the only busy people on the planet, but it is true that we are out of enough super-hackers. There is one and only one
Owen Taylor. Even though he makes a perfect chair at the board, there are multiple other places that he suites quite as well (and much better) that no one else fits.
That's why I think voting for people who know how to run a board is a better strategy than voting for those who have better goals or are better hackers. My two cents.
That said, I'm also
running, not because I think I make a good board member, no I don't (think so). But if GNOME is our little family, I don't mind offering what I can do, at any level. I don't see myself elected this year, but more of like as a way to get started in getting involved in the project on levels other than hacking.
[Other than that, attended the
college puzzle challenge on Saturday. Twelve hours of puzzle solving in a team of four. We just did nine. So much fun.]
Toronto community
Wrapped up at
UBZ at the weekend, went
shopping with Shahab and Mona, and finally headed back home.
Yesterday
Jeff Waugh arrived around 4ish. Apparently his laptop, wallet, camera, and phone were stolen at a restaurent in Montreal, so he's got a crappy laptop and he spent as much time as he had reconstructing his talk. The
talk went pretty smooth. Some fifty people showed up.
Jody Goldberg was there. John McCutchan the inotify developer too. Andrew, Tom, and Deepak from Red Hat Canada. The
TLUG guys. Students, and a lot more. We headed to O'Grady's across the street in a big group, had lots of beers and got home just after midnight.
This morning we woke up pretty early, 7ish. Had breakfast here at
linuxcaffe, with some of the people from last night, and still chatting and checking mail here. Very nice place.
Time to get back to normal life after ten days of living the hacker life only. Photos should wait a bit.
Glib bithacks
Because one blog post is typically not enough after a long day. Was looking into replacing glib Unicode tables with stuff generated with my
awesome compressor (lack of self-confidence!) that I found the functions accessing those tables are in fact more in need of some love.
Here is the problem: There's an enum of some 30 entries, which are Unicode general categores, like this is a letter, this is a digit, etc. You want to test whether a character is in one of a few of these classes. Typically you write something like this:
#define ISDIGIT(Type) ((Type) == G_UNICODE_DECIMAL_NUMBER \
|| (Type) == G_UNICODE_LETTER_NUMBER \
|| (Type) == G_UNICODE_OTHER_NUMBER)
If you are efficiency-concious, you may convince yourself that gcc takes care of it. Which it doesn't.
I solved this problem in FriBidi by assinging specially built values to my enum entries, but later found that that's overly complex for the task at hand. And forces you into 32-bit enum entries too, which may not be suitable. Here is part of the patch for your visual enjoyment, of my new solution:
-#define ISDIGIT(Type) ((Type) == G_UNICODE_DECIMAL_NUMBER \
- || (Type) == G_UNICODE_LETTER_NUMBER \
- || (Type) == G_UNICODE_OTHER_NUMBER)
-
-#define ISALPHA(Type) ((Type) == G_UNICODE_LOWERCASE_LETTER \
- || (Type) == G_UNICODE_UPPERCASE_LETTER \
- || (Type) == G_UNICODE_TITLECASE_LETTER \
- || (Type) == G_UNICODE_MODIFIER_LETTER \
- || (Type) == G_UNICODE_OTHER_LETTER)
-
-#define ISMARK(Type) ((Type) == G_UNICODE_NON_SPACING_MARK || \
- (Type) == G_UNICODE_COMBINING_MARK || \
- (Type) == G_UNICODE_ENCLOSING_MARK)
-
+#define IS(Type, Class) (((guint)1 << (Type)) & (Class) ? 1 : 0)
+#define OR(Type, Rest) (((guint)1 << (Type)) | (Rest))
+
+
+
+#define ISDIGIT(Type) IS((Type), \
+ OR(G_UNICODE_DECIMAL_NUMBER, \
+ OR(G_UNICODE_LETTER_NUMBER, \
+ OR(G_UNICODE_OTHER_NUMBER, 0))))
+
+#define ISALPHA(Type) IS((Type), \
+ OR(G_UNICODE_LOWERCASE_LETTER, \
+ OR(G_UNICODE_UPPERCASE_LETTER, \
+ OR(G_UNICODE_TITLECASE_LETTER, \
+ OR(G_UNICODE_MODIFIER_LETTER, \
+ OR(G_UNICODE_OTHER_LETTER, 0))))))
+
+#define ISMARK(Type) IS((Type), \
+ OR(G_UNICODE_NON_SPACING_MARK, \
+ OR(G_UNICODE_COMBINING_MARK, \
+ OR(G_UNICODE_ENCLOSING_MARK, 0))))
Yes, good old Pascal-like bit-sets! The real patch is much longer. As a side benefit, the macros only expand Type once, so you don't need to allocate an intermediate variable for it. How's that?
Pango climax
So I committed patches like crazy today,
rm -rfing my pango trees and closing bugs one after the other. Federico applied one of his patches, and will do the other soon. After having no commits for one month, Pango has got
more than 100 lines of ChangeLog since yesterday.
Remaining small item is finishing the patch to short-circuit mini-fribidi on unidirectional text. Then I can go on to
making Pango follow UAX#29, which needs a rewrite of text-boundary algorithm.
That's for now. Last but definitely not least, Matthias Clasen has been the guy behind the scenes reviewing all my and federico's patches. Rock on mclasen.
Montreal Pango Summit
Billy Biggs drove over from Ottawa yesterday and we spent about 10 hours straight optimizing Pango even more.
Billy have started looking into
computing log_attrs lazily. We didn't know about the open bug though.
I committed my mini-fribidi and opentype patches, then produced a more efficient mirroring table for glib using
my tools. Used the tools to make a better
gunichar->script table for Pango too.
Last night did some profiling and found that calling pango_fc_font_lock_face() and pango_fc_font_unlock_face() from static functions is causing several redundant PANGO_IS_FC_FONT checks, that show up in the profile (around 1%). So ripped them off.
Today I committed more bits: Federico's quark and John Rice's G_MODULE_BIND_LAZY mini patches.
All in all, very productive so far.
To be continued...
False alarm on g_utf8_offset_to_pointer
My investigations suggest that the current code is indeed the best to have in glib. Imagary first:
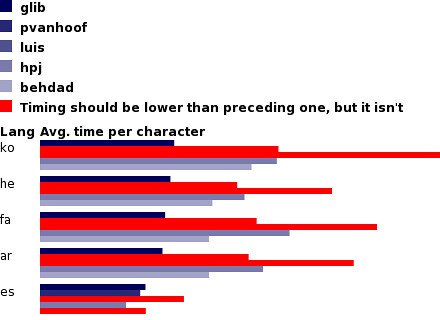
- glib is the original glib code that jumps over each character using a lookup table. As you see, the performance is kinda linear on the number of characters.
- pvanhoof is this post, checking for *s < 192 before looking up in the table
- luis is this implementation, it goes over all bytes, checking which ones are start of character. This doesn't work good for multibyte characters at all. As you can see, it's exactly three times slower than the original code for Korean.
- hpj is this implementation, using a very custom logic working a 32-bit word at a time. Again, it's pretty slow on Korean, since it's linear in the number of bytes, not characters.
- behdad is my implementation below. It works a word at a time, using bit hacking to count the number of start-of-char bytes. It's faster than the other proposed patches for most cases, but still slower than the original code. BUT, since it works a word at a time, I expect it to beat the original code on 64-bit architectures. :-) Here it is:
#define WORDTYPE guint
#define REPEAT(x) (((WORDTYPE)-1 / 0xFF) * (x))
gchar*
behdad_utf8_offset_to_pointer (const gchar *str, glong offset)
{
const WORDTYPE *ws;
const gchar *s;;
ws = (const WORDTYPE *)str;
while (offset >= sizeof (WORDTYPE)) {
register WORDTYPE w = *ws++;
w |= ~(w >> 1);
w &= REPEAT(0x40);
w >>= 6;
w *= REPEAT(1);
w >>= (sizeof (WORDTYPE) - 1) * 8;
offset -= w;
}
s = (const gchar *)ws;
while ((*(const guchar*)s)>>6==2)
s++;
while (offset--)
s = g_utf8_next_char (s);
return s;
}
(Update: code updated to rip off one more operation)
Surprisingly, unwrapping the loops slowed things down for all implementations! Should have something to do with pipelining. Makes some weird kind of sense to me.
The code for the benchmark is attached to this
post to mailing list.
Update: As Morten
shows, when dealing with words, one should align access, or it dumps core on Sparc and other weird architectures.
Optimization army
[Nice song mentioned by
Havoc.:
Brownsville Girl]
Tomorrow
Billy is coming here to UBZ, so we can clean up Pango patches and (if federico and mclasen are around), commit them. Looking forward for a hard-working day with him.
Amazing to see so many people have responded (on
planet and
list) to
Federico's call for optimization on g_utf8_offset_to_pointer. Apparently many people are (really) ready to help, should you give them a concrete problem at hand. And from
my own experience and this case,
Planet GNOME is a much better place to dispatch such tasks than any mailing list. It just triggers so many random readers that never get your message on the mailing lists.
As for the offset_to_pointer problem, I don't quite agree with
Morten. Of course, if there are invocations of this function in a loop, that causes square time and should be changed, but I believe this function can still show up in benchmarks from being called so many
constant times. Not sure this is the case in the original backtrace that exposed the problem though.
Anyway, I like
Luis Menina's approach of simply going over all bytes and counting how many have the two high bits not equal to 10.
hpj's approach of handling a 32-bit word at a time is interesting too, but (much) more complex. Mixing the two, I have some ideas about it. We will see tomorrow.



