McEs, A Hacker Life
GNOME and Ubuntu talk: Jeff Waugh in Toronto
Jeff Waugh brings the
BadgerBadgerBadger tour to town, and talks about all the amazing things happening in the GNOME and Ubuntu projects, from the new multimedia framework of the GNOME project, to the .NET application development environment for the Linux desktop, to the GNOME project deployment on the Nokia internet tablet devices. Expect a high wow-factor and lots of Ubuntu CDs and stickers.
Where: BA1170, Bahen Building, 40 St George St, Toronto.
When: Monday November 07, 7:00--9:00PM.
We probably go for a drink/dinner afterwards. Please forward to interested parties, lists, newspapers, etc.
Bio:
By day, Jeff Waugh works on Ubuntu business and community development for Canonical. By night, he rides shotgun on the GNOME release juggernaut and plots the Open Source blogging explosion with Planet. Waugh is an active member of the Free Software community, holding positions such as GNOME Release Manager (2001-2005), Director of the GNOME Foundation Board (2003-2005), president of the Sydney Linux User's Group (2002-2004), and member of the linux.conf.au 2001 organising team. Jeff was awarded the Google-O'Reilly Open Source Evangelist Award for his contribution go Ubuntu and GNOME projects this last Summer. He is a card-carrying member of Linux Australia, but does not say "mate".
GUINNOME
 Update:
Update: It's real.
Update2: If the image looks corrupted, it's a
Flickr bug. Click on the image and choose another size in the mean time.
UBZ days -1 and 0
So
Ryan and I arrived in Montreal last night. Ryan checked in to the hotel and I called a friend of mine Shahab in, and just
hub and his girlfriend Nancy from Ontario showed up too, so we walked up to downtown, had dinner when Mona joined us, and landed in a bar just to talk about all the
strip clubs in Montreal. I used my right to smoke in bars in Montreal.
I also got a cool photo at the bar that I cannot post yet, since I've left my laptop (and other stuff) at Ryan's hotel room and he's at hub's place now. Got to catch up.
Met
jdub today. Apparently there's nothing happening today, except for Cannonical people meeting.
Anyway, looking forward for an awesome week of hacking.
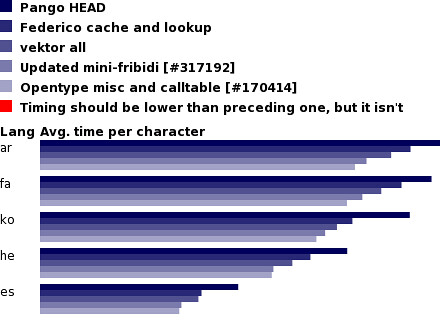
Optimizations continue on the Pango front
Work is in progress 24/7 on irc.gimp.org's
#performance channel by warriors
Federico Mena-Quintero and
Billy Biggs (read their latest reports) on optimizing Pango. The results are
very promising so far, at least five patches exist, each with at least 5% speendup in a wide array of scenarios. I tested my new FriBidi and OpenType optimization stuff last night, here are the results, thanks to Federico's benchmark tools:
Massaging Board Meeting Minutes Data
Following up on the discussion about
reducing the GNOME Foundation board size from 11 to 7, I used some shell and awk to get some attendance statistics out of the meeting minutes that
Daniel has been sending out.
First we need to download all the traffic on the
foundation-announce list for the year of 2005 (only):
for year in 2005; do
for m in `seq -w 12`; do
month=`date +'%B' -d $year/$m/01`;
wget -O - http://mail.gnome.org/archives/foundation-announce/$year-$month.txt.gz |
gunzip > foundation-announce-$year-$m$month.txt;
done;
done
Now we want to figure out how many meetings each of the board members has attended, missed, or sent a regret. A bit of awk does exactly that:
cat foundation-announce-2005-* |
awk '
/^(Attendance|Missing|Regrets):?$/ {mode=$0; state=0; next;}
/^$/ {if (!state) state++;
if (state>1) mode=0;
next;}
/:$/ {mode=0; next;}
/^=*$/ {next;}
/^ / {state=2;
if (mode) print mode" "$0;}
' |
sed '
s/ *(.*//;
s/ */ /g;
s/David Neary/Dave Neary/g;
' |
sort |
uniq -c |
sort -n -r
And here is the output:
13 Attendance: Tim Ney
13 Attendance: Owen Taylor
12 Attendance: Murray Cumming
12 Attendance: Federico Mena-Quintero
12 Attendance: Daniel Veillard
11 Attendance: Jonathan Blandford
10 Attendance: Dave Neary
8 Attendance: Luis Villa
8 Attendance: Jody Goldberg
8 Attendance: Christian Schaller
7 Attendance: Miguel de Icaza
4 Regrets: Miguel de Icaza
4 Missing: Christian Schaller
3 Regrets: Luis Villa
3 Regrets: Jody Goldberg
2 Regrets: Jonathan Blandford
2 Regrets: Dave Neary
2 Missing: Miguel de Icaza
2 Missing: Luis Villa
2 Missing: Jody Goldberg
1 Regrets: Murray Cumming
1 Regrets: Federico Mena-Quintero
1 Regrets: Daniel Veillard
1 Regrets: Christian Schaller
1 Missing: Dave Neary
Inverse Distribution
Yesterday
Divesh Srivastava was giving the departmental colloquium here about
Streams, Security, and Scalability. Interesting talk generally, but there was one point I particularly liked, and think the idea can be useful in other scenarios too:
Suppose that you are monitoring the traffic of your lab's network, and would like to detect when a new internet worm is emerging. Note that you don't even know what this new work looks like. Here is how it works: take packets for one-minute (whatever) worth of traffic, form the
n-grams in the input (start with bigram or trigrams, but 4-grams and above are not out of question either), and distribute them into bins based on their frequency. You get an
inverse distribution which for given
x, tells how many
n-grams have frequency
x. Now if the traffic is random-enough, this inverse distribution function should follow a
Poisson distribution, which is a deformed bell curve of some kind. Draw the graph of the function (may want to use logarithmic x axis.)
Now as a new internet worm becomes epidemic, the frequency of the
n-grams in the worm payload get exponentially(?) higher and higher, and in the graphic view of the function, you see another bell curve raising higher and higher and farther to the right. That's a new worm spreading!
This paper contains the details, as well as ways to trigger this automatically.
Stereograms
caleb: Have you checked
stereograph for linux? It's a neat project on sf.net. The cool thing is, it can produce stereograms for transparent objects like glass! Check the one in
this page.
That said, stereograms hit Iran around 1994. I remember getting an Iranian reprint of
Magic Eye I that had an ad about a big prize (~$4000 back then, which was worth quite a lot more in Iran) for the first one who writes a computer program to produce stereograms, before the end of the (Persian) year. I got the book as a new-year gift... Anyway, where's your code by the way?
Free Software and Open Source Symposium
[Off topic: An initial Google Summer of Code report is
out, with partial list of projects and map of participants.]
Yesterday (Monday) I attended the 4th
Free Software and Open Source Symposium at
Seneca college. Seneca is located in the York University campus by the way.
It turned out to be a good way to spend a day in leisure. The opening address,
Open Source 101: Introduction to Collaboration, was yet another Creative Commons Canada talk, but the presenter (
Marcus Bornfreund) had this ironed out style that gets deep in. One point he was stressing was: there's no Open Source software, there's software released under an Open Source license. Not many people agreed though.
Next slot I made the mistake of going for the
Python Power -- Learning, Teaching and Doing with the World's Easiest Programming Language talk, which can be shortened without loss of information in: "Python is a very easy language, but it's not a toy language." Eek.
Skipped the slot before lunch. After lunch was
LTSP - Changing the Rules of the Desktop World by Jim McQuillan. Now this one I could easily relate to. Jim was, kinda, one of us... compared to most of the rest of the attendees who were mostly
consumers of Open Source software, and affiliated with a small company (of their own.) Don't bite me on this point though. Jim's presentation was, needless to say, interesting. Lesson learned: Our X terminals at the school crash when we open a lot of tabs with lots of graphics in Mozilla most probably because they have not set up swap space for the X terminal, so, when X fills up the available memory, kernel
OOM-kills it. Simple, eh? Poor us.
Next talk was
The Life-cycle of Open Source: The Renaissance of X, by Seneca's
Chris Tyler. Even though I knew all the stuff he talked about (the history of X, recent rise, etc.), his presentation was awesome: presented in the
Lessig method, with a remote and synchronized to the millisecond. Really enjoyed it.
The final presentation was a weird one,
Ruby, Blackboard and the Challenge for Open Source by
Stephen Downes.
Read
Fernando Duran's account of the conference for more detailed information.
From Half-Marathon to Capture the Flag

Last weekend I joined
Farhang for the
Toronto half-Marathon. Now, the last time I was on
practice was in June, and my longest was 10km, and that was all making me a bit nervous. Stayed the night before the race at Farhang's, who cooked a tasty pasta for everybody. The weather was just perfect. We started around Finch & Yonge, headed down Yonge St. and turned east just before Bloor St., where we headed South by in a trail by Bay View and finally entered downtown through Lakeshore Blvd. Headed North at University Ave. and turned the whole way around the Queens Park to the finish line.
I had quite a bit of problem getting started, something like I drank too much water in the morning. So after 7km, I let Farhang go and backed up for a while at a Second Cup! I started again and made it straight to the finish line. After the lengthy stop I had, I aimed for 2:15, and unbelievably my gun time was 2:15:00.2! Chip time a few seconds shorter... Not a good time, I know, but then again, I was not even sure I can finish it, so, I'm happy with it. Official results
here.
This past Friday night, with
Hossein and
Oktie, we took part in the
last Capture the Flag game of the year, in the entire
University of Toronto downtown campus. Around 500 people showed up.
Map. We were in Team Danger (red), and my flat was in fact in the our zone, were my office was in the other zone.
The game started around 9PM. First we were defending, were each of us tagged a bunch of yellow guys. Around 10:30 Hossein and I left base to go for their flag. After jumping over a couple (public) fences and passing through four or five buildings (all needed key to access at that time of the day), we finally found their flag, just behind the Robarts library. We were still planning with this other red guy we found there when whistles were blown and everybody started leaving the game. So we all gathered in Queens Park. The game was ended prematurely since it was after 11PM, nobody scored yet, a (small) accident happened and police was called in. Very joyful though.
On Saturday night, Ehsan was around, so spent the night playing cards with Amir and Hossein, just like we all used to do back in undergrad. We played poker and blackjack though.
On a side note, Pouria finally wrote us back from Kabul. He's writing a
weblog of his experience there.
I can see through your masks
[Announcement: There's a new list:
performance-list gnome org. All invited.]
Over the past two weeks I found somebody accessing my departmental Linux account using password and running mallware. The first time it happened, I was in great shock. Fortunately the admins confirmed that password authentication was used, so my precious private key on my laptop was not stolen. So I convinced myself that a friend's Windows machine I used to check mail was the source of the problem. When it happened a second time though, it left only two choices: My laptop, and the Linux box I use to check email when I'm in University of Toronto at Scarborough on Thursdays. It's a professor's office box, not a public box.
Anyway, I investigated the box in question, and indeed it was infected, by a rootkit and lots of other
bad things. I didn't have root access, that made investigations a bit harder, but here are a couple of my observations that are worth noting:
- While the rootkit had process-hiding capabilities in place for
ps, I happened to run pstree and were surprised to find a suspicious process (a process called "smbd -D" with an space in it.) So, when in doubt about ps, give pstree a try. Checking with /proc does the job too, but it's harder.
- This one is more useful. Since I was not logged in as the root user, I couldn't see where
/proc/*/exe points to for processes owned by other users (included the root user), but I figured out a way around it: Stupidly enough, the kernel lets you see the /proc/*/maps file for any process, and not surprisingly, the first line in that file corresponds to the image being run, which is exactly what the /proc/*/exe file would have pointed to, could you ever see!
Pango hacking revisited
First, good news,
Lars Knoll sent
Owen Taylor and I a note about merging the OpenType Layout code in
Pango and Qt. So, seems like the last item of
my Pango roadmap will be RESOLVED FIXED without me doing all the work. Sweet.
The rest of this note is mostly in response to
Federico's blog posts on Pango. For the first time, I'm advertising a piece of code I wrote a few years ago for compressing data tables efficiently. So it may be of interest to people not interested otherwise too.
In response to Federico's
Glyph lookups (aka. Profiling the file chooser, part 5), my only concern is that of thread-safety, and scalability to multithreaded applications on multiprocessor systems. About thread-safety, I don't see any means to prevent race conditions when accessing the cache. Scalability is another well-known issue, my concern is that the cache may turn out to be a bottleneck when multiple threads try to access it in parallel. Discussion in the
GMemChunk bug looks relevant.
Now somehow I managed to miss the excellent work in Federico's next report, the
Pango gunichar->script and paired-character mappings work (aka. Profiling the file chooser, part 6) There's a lot of good points raised in that post, and I
damn wish I could make it to the
GNOME Summit (as a course in anger management, I really should keep reminding myself that I hold an Iranian passport more often.) Unfortunately Owen doesn't blog about work that often, and in fact it's a while since I last noticed him working on Pango. But I will try to find him and manage integrating some of these works in November. Now to the technicalities:
There are three main offenders that Federico, Billy, and Owen tackle: gunichar->script mapping, paired-characters table, and pango_log2vis_get_embedding_level. This last one is in fact
FriBidi code copied inside Pango. I'll cover it last. The two other problems are both looking up a property for a Unicode character, and the current code is using a binary search on the run-length encoded tables. That's indeed the native approach, and slow. Now you may be amazed to know how these two relate to FriBidi too!
In FriBidi, currently we have two Unicode data tables: One mapping Unicode characters to their bidi-category, some 19 different values; the other one mapping Unicode characters to their
mirrored characters if any, which is basically an identity mapping for almost all characters, except for things like parentheses and brackets, which are mapped to their pair. If these two kinda look like the two tables in Pango, you've got my point. So I'll elaborate on how we handled them in FriBidi:
Initially when FriBidi was written in 1999, a bsearch table generated by a Perl script was being used for both bidi-types and mirroring-char. Then in 2000, Owen sent a patch to use a two-level lookup table that drastically improved the performance. At that time Unicode still was a 16-bit character set! So the two-level was a simple [256][256] split. Later on when I showed up and started hacking all around FriBidi. Unicode jumped to the current 21-bit setting and all in a sudden there was not trivial best split. So I retired the Perl script, and wrote a generic table compressor that given the maximum number of lookups (levels) you can afford, it finds the optimal break down of the table and generates C code for that. Later on Owen suggested to use indices instead of pointers, to reduce relocation time. That was done, and we had a shiny compressor which was able to compress the bidi-type data for the whole Unicode range into 24kb for a two-level table, or 5kb for a four-level table, or 2.5kb for a nine-level table, or anything in between! We left the mirroring code intact, using the bsearch (that's not used in Pango though, Pango uses mirroring functions from glib). Later on when I was working on the new FriBidi code (not released yet), I improved the compressor more, and decided to use it for mirroring table too. Now, like any good compressor, it will compress pretty good if the (information theoretic) information in the table is small compared to the size of the table, which is the case for most of Unicode properties, that take one of a few values, with some kind of locality effect. For mirroring it was a bit different, most of the characters were mapped to themselves. What I did was to create a new table, which was the (mirrored_unichar - unichar) value. Now this new table was
really sparse. Applied the compressor, lo and behold, down from 2656-bytes to 944-bytes, and instead of bsearch on a 322-entry array, to 4 lookups. Woot!
Now you would say the catch? The catch is that when I wrote that compressor code back in 2001, I was just moving on from programming contests to Free Software hacking, and using one-letter variable names in a backtrack still seemed like a good idea. The code works amazingly good though, and I do actually go take a look at it once in a while to internalize how to
not write code. I have improved since.
The stuff:
Ok. I think the two samples are simple enough to get anybody going with the compressor. Would be interesting to see how tables generated using it will perform in Pango. Other than that, The existence of this problem in the first place is a good reason why
I believe that all of the
Unicode Character Database properties should be efficiently exposed in a central library, part of
Project Giulia.
One final paragraph about pango_log2vis_get_embedding_level performance. There's been
some discussion about short-circuiting that function for LTR-only text, and that's on the horizon, but probably after updating the mini-fribidi code with upstream. That said, some of the performance problems with that function will be solved after resynching and enabling the trash-stack. Currently it's malloc()ing about twice per word of text.
Links, Movies, and (other) Trivia
[First attempt towards emptying my backlog]
Links everyone should have seen by now:
Random movie-related stuff:
- Watched Night on Earth (1991), a typical Jim Jarmusch film: divided into a series of shorts like Coffee and Cigarettes, all pieces coinciding in time like Mystery Train (1989), soundtrack (partly) by the Tom Waits like the Down by Law (1986), and a comedy starring Roberto Benigni like all of them. I'm still to understand how he could produce a so different movie like Dead Man (1995)! All of them highly recommended. In fact Jarmusch is my favorite director / movie writer, sharing only with Krzysztof Kieslowski.
- Also watched In Good Company (2004). Good for dinner-time with friends only.
- In my priority queue to be blogged for a while, The Keeper: The Legend of Omar Khayyam (official site). Didn't like the synopsis, but should really check it out.
- Last, but definitely not least, Sex & Philosophy (2005) by distinguished Iranian director Mohsen Makhmalbaf. Again, not watched yet, but the script was pretty good. Written in form of dialogs, it moves around concepts of what love really means. A guy timing his "happy times". If you ask me, not quite irrelevant to In Praise of Love (2001). Liked this dialog particularly, although it's not quite around the core theme (translation's mine):
- (to the poet) These guys are your fans, why don't you spend five minutes with them.
- John, they are fans of my poetry, and killers of my time. My whole life was spared in these 5-minute moments. The minutes are called time, but in reality they are one's life. One's life is short, and one should not be embarrassed to protect one's life.
Reminds me of Bob Dylan quote: Just because you like my stuff doesn't mean I owe you anything.
Misc:
Behdad's Pango roadmap
[I updated the
previous post about gnome-terminal performance extensively. In short, g-t is faster than xterm. Xft is to be blamed (Hi Keith) :-D]
I see
Pango mentioned quite a lot these days, mostly as the bottleneck to desktop rendering. So I thought I may write a bit about my view of how things are going in Pango.
First, in reply to
Federico's comments:
- Zero is indeed a valid Unicode character, but not used that much, like it's not used that much in C strings.
- I like your patch. I don't quite like a cache of 1kb or 2kb per font per size per process, but hey, we just ripped off 100kb per process in fontconfig... so. Please post the patch on bugzilla. Owen doesn't scan planet for patches ;).
- I think your patch performs good enough to be applied, without too much worrying about CJK. Most of the scripts encoded in Unicode fit in a block, and so your cache performs pretty good. For those that it doesn't, all you lose is still small compared to the route you should take anyway (cairo / xft).
- It's true that Pango cannot be easily optimized. All the time spent inside is balanced. That's were we need more tools to exactly see what's going on. But I don't agree that optimization in Pango modules is worth it. The text rendering pipeline is so deep and heavy that the modules are really negligible anyway. And if you really want to do that, just keep it on bugzilla and there are people that know how any particular module works.
Generally, I'm quite amazed by how stable Pango has become these days, no major features lacking, not much serious bugs. Now here are the major items in my Pango todo list, most of them are in bugzilla already:
- Update mini-fribidi to match upstream. (patch)
- Update line-breaking to follow Unicode 4.1 UAX#14. (patch)
- Rewrite word-boundaries to follow Unicode 4.1 UAX#29. (working)
- Optimize the OpenType code (patch), and fix a couple bugs too.
- Add back Arabic shape-to-presentation-form. May merge Arabic joining algorithm in Arabic and Syriac modules too.
- Review Damon's TeX-style justification. (patch)
- Simplify the module interface, factoring away the common bits (in particular, mirroring and reordering which don't belong in the shaper at all). I would like to add one more level before shaping, something like language analysis, which doesn't depend on the font, only language/script. Some bugs with Arabic shaping will be really solved that way. Last but not least, Owen suggested, to aim for a declarative module API for simple modules, where you only specify a table of OpenType tags.
- Finally, merge the OpenType code with Qt's copy, move it away to fd.o, make a copy in Pango.
Now how many of these I'll make for 1.12, no idea. The ones with a patch are mostly waiting for
Owen's review.
[damn, internet is slow these days.]
Update:There's
this huge patch to shut various gcc warnings off too.
gnome-terminal performance
[Somehow I managed to not write here for quite a while. In the meanwhile, I passed another birthday. Twenty-three now.]
That gnome-terminal is damn slow is not news, but I found a silly simple test case to measure how things are going. The test case:
time for x in `seq 10000`; do echo {a,b,c,d,e}{A,B,C,D,E}; doneWith no write at all (>/dev/null):
real 0m1.436s
user 0m1.428s
sys 0m0.004s
with xterm (80x46, 10x20 bitmap font):
real 0m5.282s
user 0m1.384s
sys 0m0.032s
with xterm minimized (same settings):
real 0m4.472s
user 0m1.652s
sys 0m0.088s
with gnome-terminal (80x46, same visual size as 10x20, Bitstream Vera Sans Mono 12):
real 0m23.708s
user 0m1.388s
sys 0m0.048s
with gnome-terminal minimized (same settings):
real 0m2.833s
user 0m1.800s
sys 0m0.068s
To test the minimized case, just do a sleep 3 before the line and minimize the window after pressing enter.
Now that gives something to optimize for! Note how gnome-terminal's pseudo-terminal emulation is in fact faster than xterm's, since when minimized, g-t is faster. All we need is a hero to rip off some 50% of that rendering time to start with...
Update:with gnome-terminal (80x46, 10x20 bitmap font):
real 0m4.126s
user 0m1.848s
sys 0m0.088s
with xterm using xft (same Bitstream Vera Sans Mono 12, run by
uxterm -fa 'Bitstream Vera Sans Mono' -fs 12):
real 0m27.334s
user 0m1.444s
sys 0m0.036s
Moreover, if I resize the windows to 80x4:
with gnome-terminal (Bitstream...):
real 0m7.480s
user 0m1.884s
sys 0m0.088s
with xterm using xft (Bitstream...):
real 0m26.638s
user 0m1.408s
sys 0m0.024s
Observations:
- xterm using xft starts flickering badly after a couple seconds.
- gnome-terminal is generally faster than xterm, when using the same font.
- gnome-terminal is far faster than xterm with smaller windows. Don't know why xterm's speed does not depend on the size of the window!
- gnome-terminal with xft rendering a bitmap font is still faster than xterm rendering the same bitmap font using X core protocol.
- Some people suggested that the scrollbar of gnome-terminal is taking a lot of time updating. I removed the scrollbar, with no change. It may be that it's still creating and updating the widget but not rendering. Somebody should look into that.
- Some other people suggested that federico's pango patch should change things, or genrally attributed the slowdown to pango. Pango is not involved here at all.
- Apparently the slowdown comes from Xft rendering the antialiased glyphs.
- Somebody suggested that copying opaque glyphs around when the background is a solid color should help. It should.
- Apparently gnome-terminal is much more important an application that I thought. Many many people are suffering from it's rather poor performance.
- Somebody should run a profiler to see what's going on. Guess they better wait for xorg 7.0 or they need an specially compiled X server to be able to profile inside it.
- g-t and vte are unmaintained these days. Seems like there are at least a few (if not a lot of) performance patches hanging around the bugzilla. Somebody should really standup and take maintainership. If nobody else does in a few days, I'm afraid I have to go for it.
- What else? Ah, Lorenzo requested a performance list to be created for GNOME. We will have some fun there.
Something funny that I experienced during these tests: My laptop's CPU would get to 70C and automatically drop the frequency to 1.2GHz (from 2.4GHz.) Thanks to the CPU Frequency Scaling Monitor applet, I figured that out, instead or reporting bogus digits. In the mean time, flipped the Vaio on the table such that it gets some more air. Have to open it for cleanup again, but it's really showing its age. Needs another backlight too. After getting a new laptop, I may use the old one for some
Wacky laptop tricks.



{kind=link}